Shane Mullins Portfolio
Clustering and Regression Machine Learning Algorithms
This report exemplifies procedures relating to both supervised and unsupervised learning techniques on both real and simulated datasets. Hyperparameter tuning to achieve improved prediction and clustering performance is the main focus. Hierarchical clustering, K-means, kernel K-means, Lasso regression, Random Forests and Gaussian processes are implemented in Python using GridsearchCV, and their characteristics discussed, in an 18 page report. Variable importance, PCA, nested cross-validation and other essential ideas are also dealt with in the context of the data.
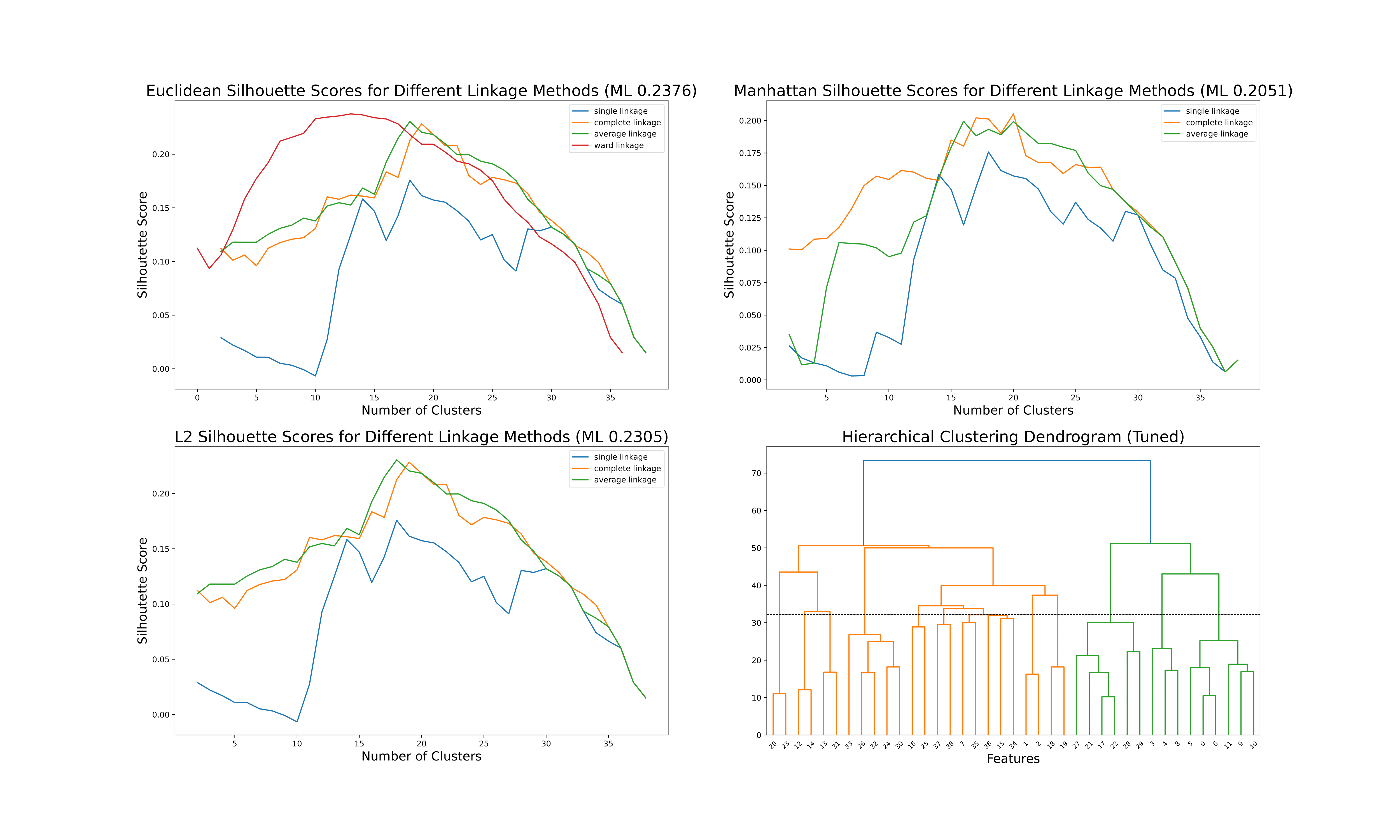
Keywords: K-Means/Hierarchical Clustering, Lasso Regression, Random Forests, Gaussian Processes, PCA, Python
Big Data Analysis
Statistical analysis on modified version of VAST 2016 Mini-Challenge 2 dataset using both Hadoop and Spark. Big Data technology facilitated the efficient use of regression and classification algorithms through Apache Spark’s machine learning library Mllib. Additionally performed rudimentary exploratory analysis using Map Reduce. The effect of non-probabilistic sampling methods in the context of Big Data was reviewed and applied to real data.
Keywords: Hadoop, Spark, Scala, Map Reduce, Support Vector Machine (SVM), Linear Regression
Analysis of Crime Rates in US Communities
The Journal of Law and Economics published an article estimating the annual cost of crime in the United States to be $4.71-$5.76 trillion dollars. The aim of this report is to use integrity-driven data analysis to obtain truthful, reliable and interpretable results about the factors that affect crime rate in US communities. Linear regression, Lasso regression, Random Forests and a K-Nearest Neighbour classifier are applied to the ’Communities and Crime Data Set’ created by UCI’s Machine Learning Repository. It was found that given the appropriate model, certain community factors, such as the population proportion of certain races and median income levels, were reasonably accurate predictors of violent crime. Results varied significantly state by state, however, Southern states were typically associated with higher crime rates.

Keywords: Regression, Classification, Python, Multiverse analysis
Computer Vision for Autonomous Vehicles (Undergraduate Thesis)
A functional object detection device was built using the Single-Shot Detector (SSD) + MobileNetV3 algorithms and the Raspberry Pi 4. The device successfully detects and discriminates between pedestrians and cyclists from within a moving vehicle. The Python libraries Tensorflow and OpenCV were used to implement the preceding functionality.
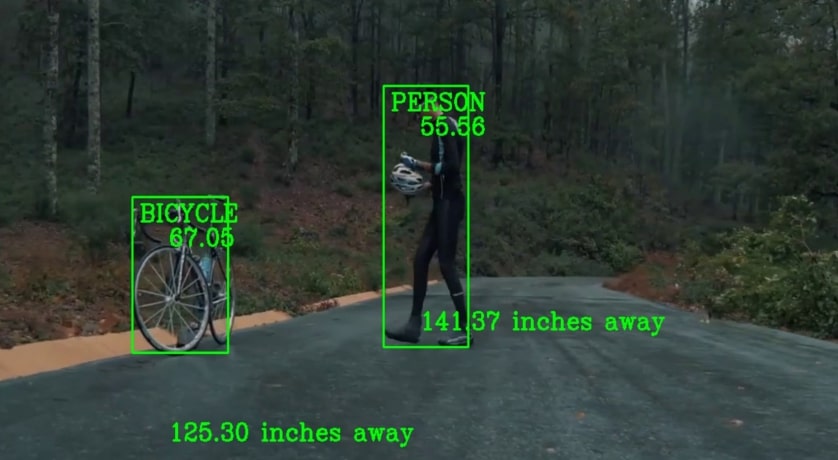
Keywords: TensorFlow, OpenCV, Object Detection
Data Poisoning Research Project
Awarded top poster presentation across whole Statistics Department at Imperial College London by both academic staff and students separately. Research falls into the bracket of adversarial machine learning. Aiming to understand what constitutes a successful Machine Learning attack through comprehensive simulation.

Keywords: Data Poisoning, Poster Presentation
Data Analysis Performed on Seattle Collisions Data
Each year, approximately 1.35 million people are killed on roadways around the world. Road traffic accidents are the leading cause of death for people between the ages of 5-29 years worldwide. It is clear that our transportation systems and attitude towards driving are important areas to focus on. Over the past 16+ years, the Seattle Department of Transportation (SDOT) has been gathering data on collisions in the city. The purpose of this report is to unveil some interesting truths about the nature of collisions in Seattle. Some interesting questions we look to answer are:
- What proportion of accidents take place whilst a driver is under the influence?
- During what period of the day do the most collisions occur?
- Is there an increasing or decreasing trend in the number of collisions per year?
- What is the relationship between road conditions and the severity of collisions?
- How accurately can we predict the severity of a collision given certain pieces of information?
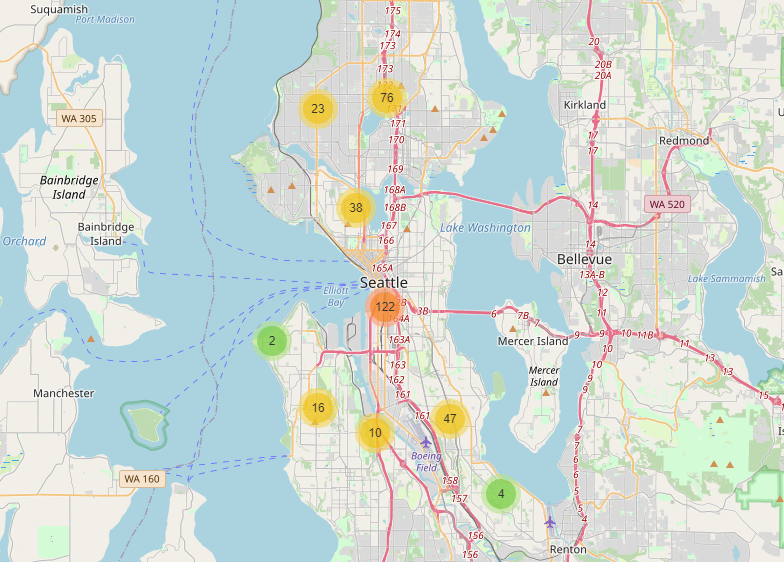
Keywords: Pandas, Matplotlib, sklearn